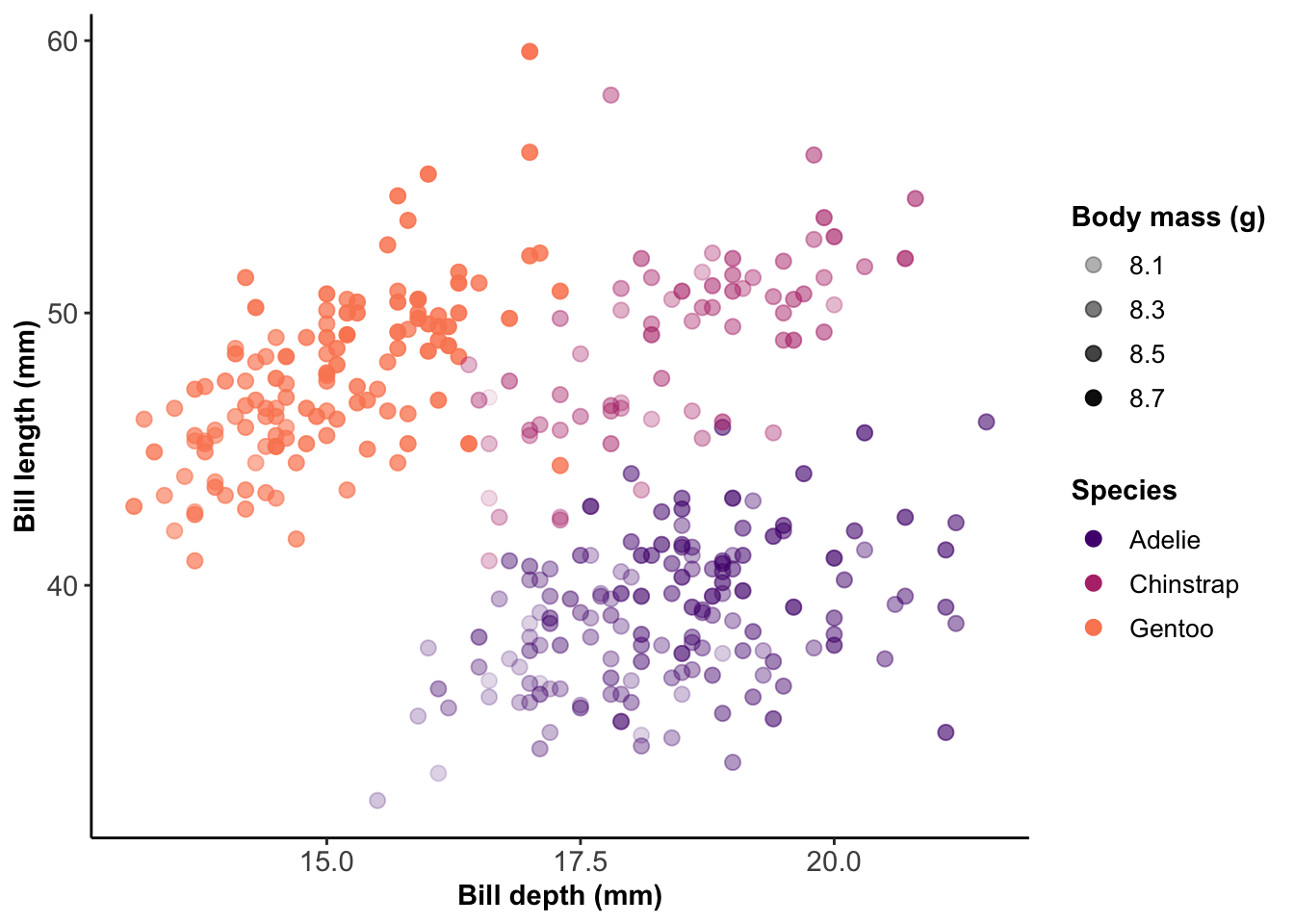
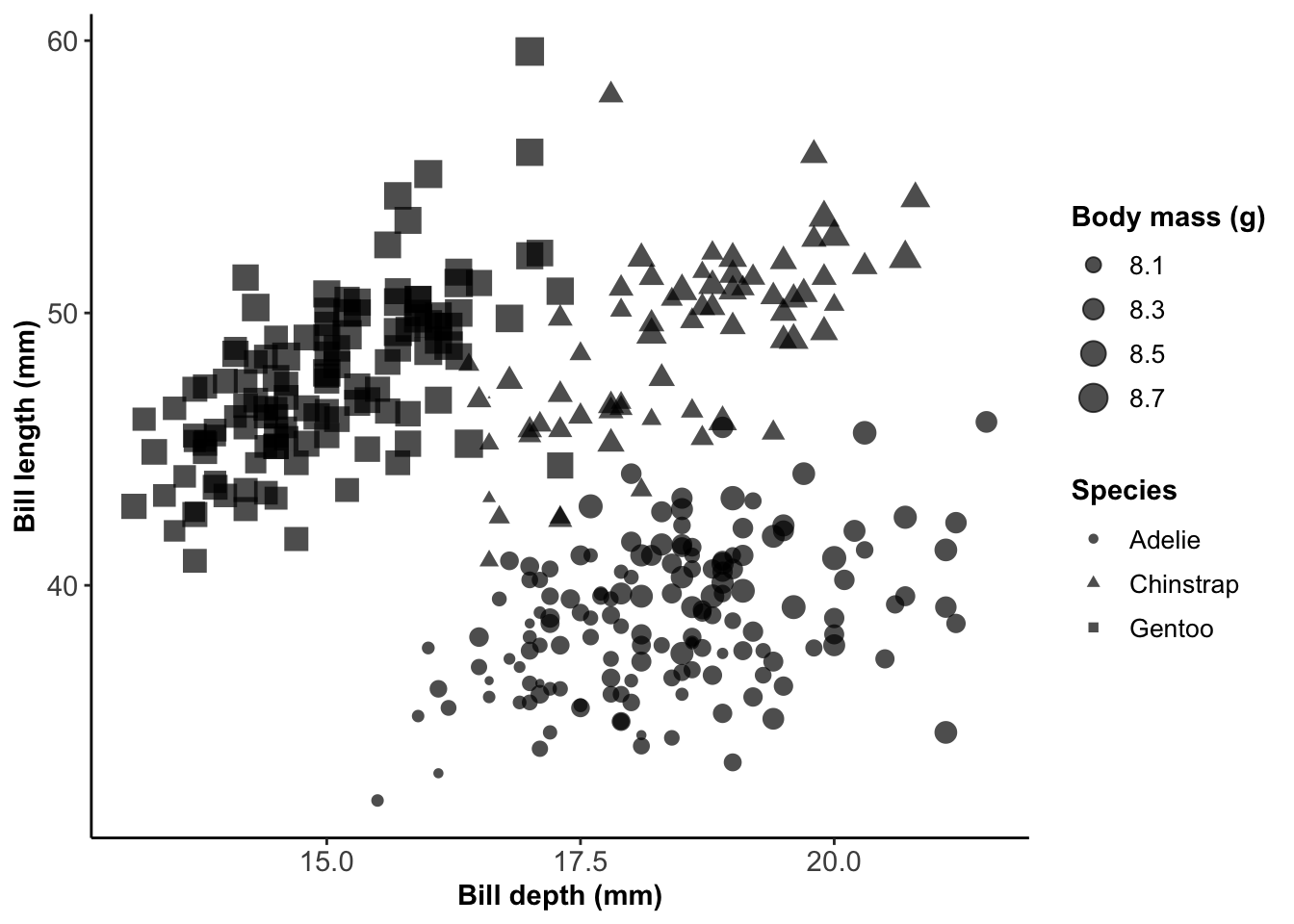
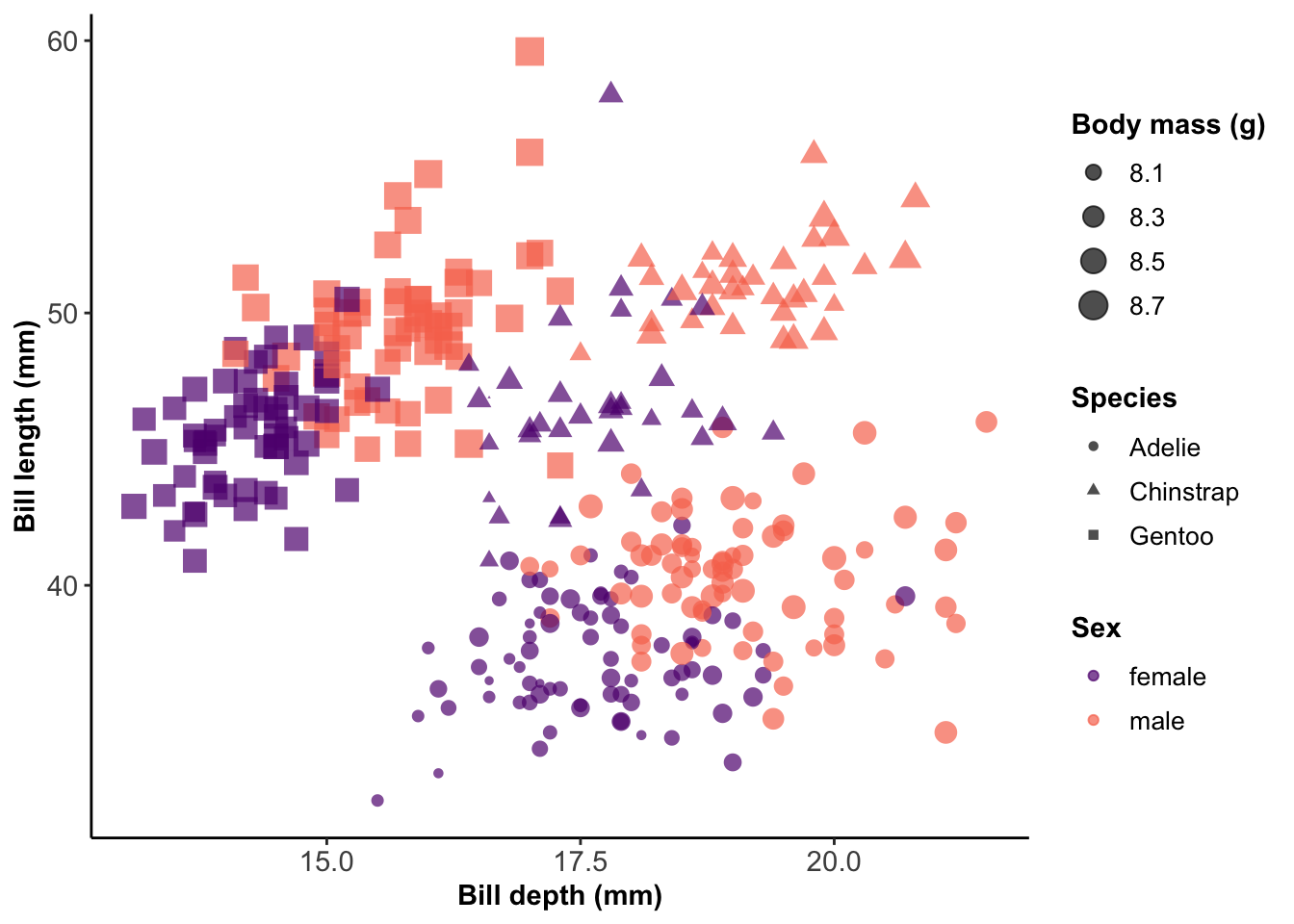
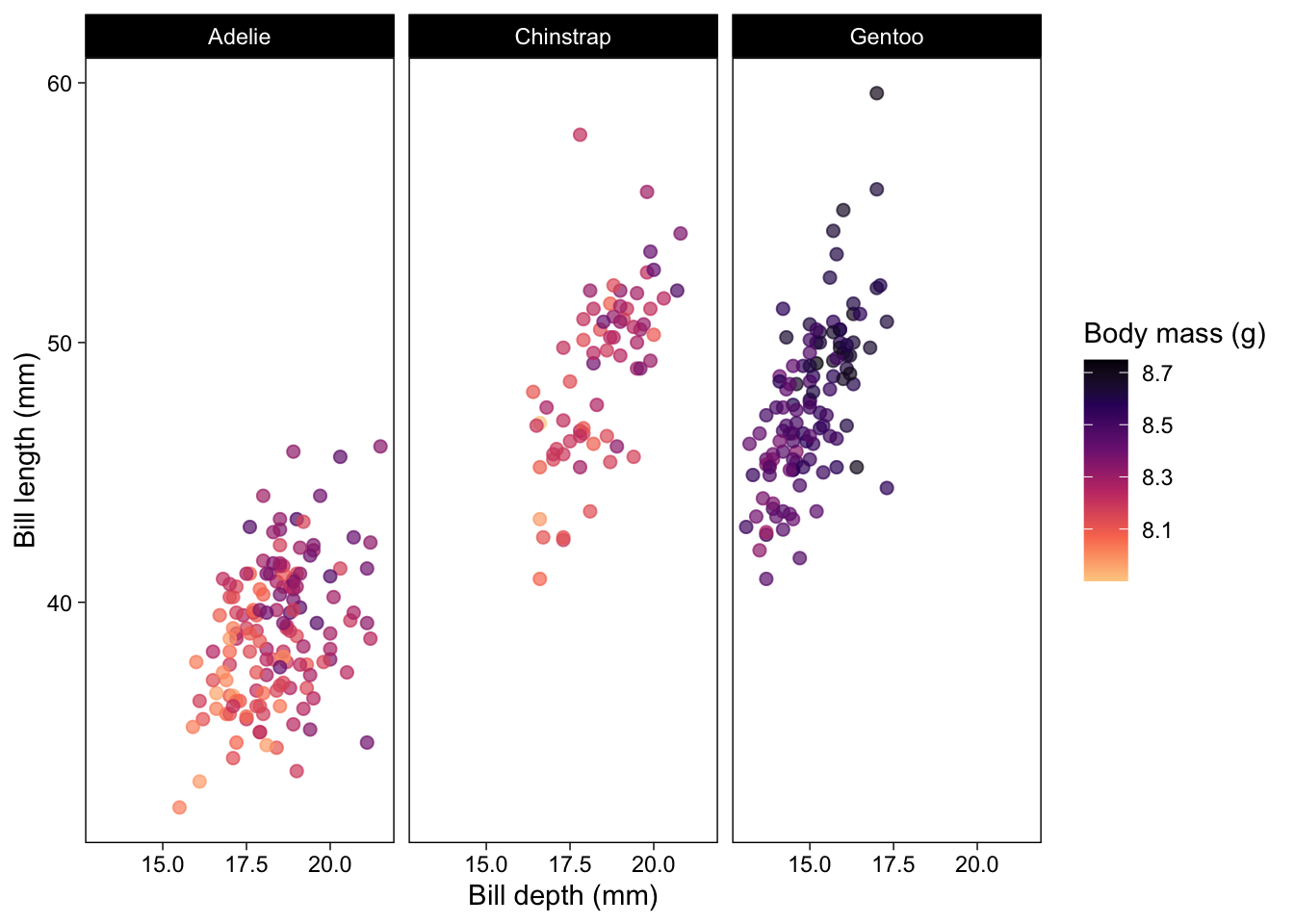
This is an annotated library of data visualization resources we used to build the BIOS² Data Visualization Training, as well as some bonus resources we didn’t have the time to include. Feel free to save this page as a reference for your data visualization adventures!
Books & articles
Fundamentals of Data Visualization
A primer on making informative and compelling figures. This is the website for the book “Fundamentals of Data Visualization” by Claus O. Wilke, published by O’Reilly Media, Inc.
Data Visualization: A practical introduction
An accessible primer on how to create effective graphics from data using R (mainly ggplot). This book provides a hands-on introduction to the principles and practice of data visualization, explaining what makes some graphs succeed while others fail, how to make high-quality figures from data using powerful and reproducible methods, and how to think about data visualization in an honest and effective way.
Data Science Design (Chapter 6: Visualizing Data)
Covers the principles that make standard plot designs work, show how they can be misleading if not properly used, and develop a sense of when graphs might be lying, and how to construct better ones.
Graphical Perception: Theory, Experimentation, and Application to the Development of Graphical Methods
Cleveland, William S., and Robert McGill. “Graphical Perception: Theory, Experimentation, and Application to the Development of Graphical Methods.” Journal of the American Statistical Association, vol. 79, no. 387, 1984, pp. 531–554. JSTOR, www.jstor.org/stable/2288400. Accessed 9 Oct. 2020.
Graphical Perception and Graphical Methods for Analyzing Scientific Data
Cleveland, William S., and Robert McGill. “Graphical perception and graphical methods for analyzing scientific data.” Science 229.4716 (1985): 828-833.
From Static to Interactive: Transforming Data Visualization to Improve Transparency
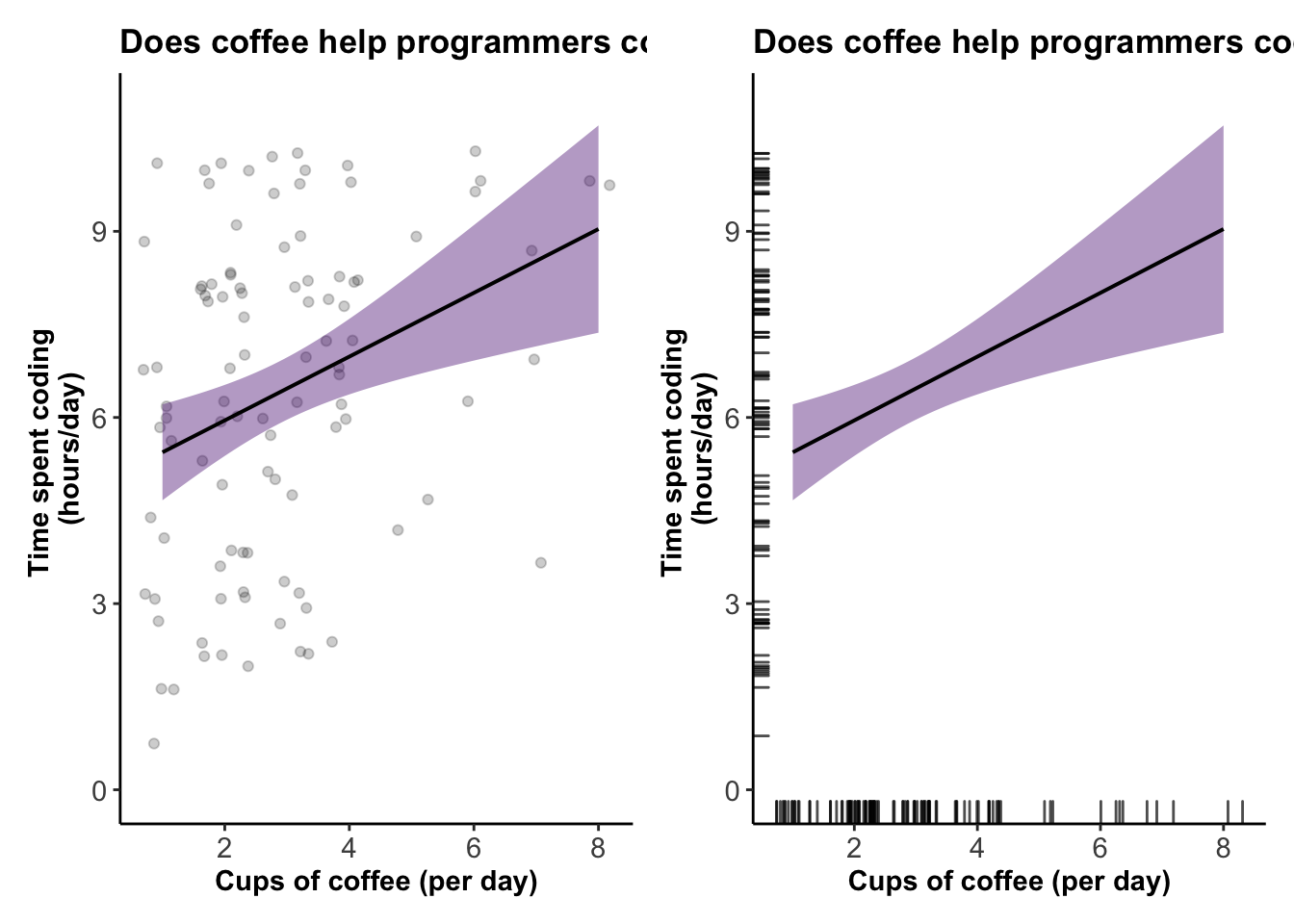
Weissgerber TL, Garovic VD, Savic M, Winham SJ, Milic NM (2016) designed an interactive line graph that demonstrates how dynamic alternatives to static graphics for small sample size studies allow for additional exploration of empirical datasets. This simple, free, web-based tool demonstrates the overall concept and may promote widespread use of interactive graphics.
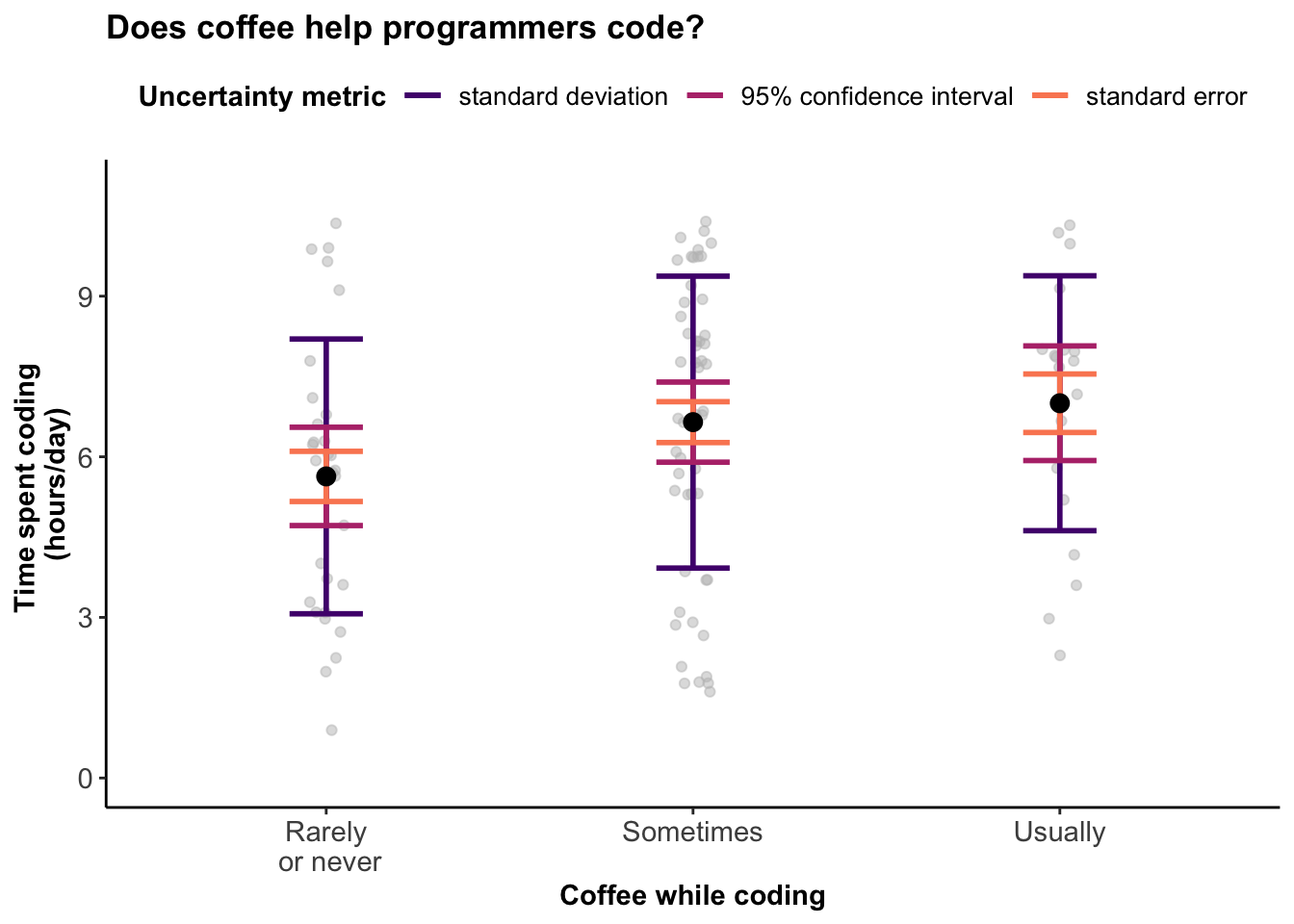
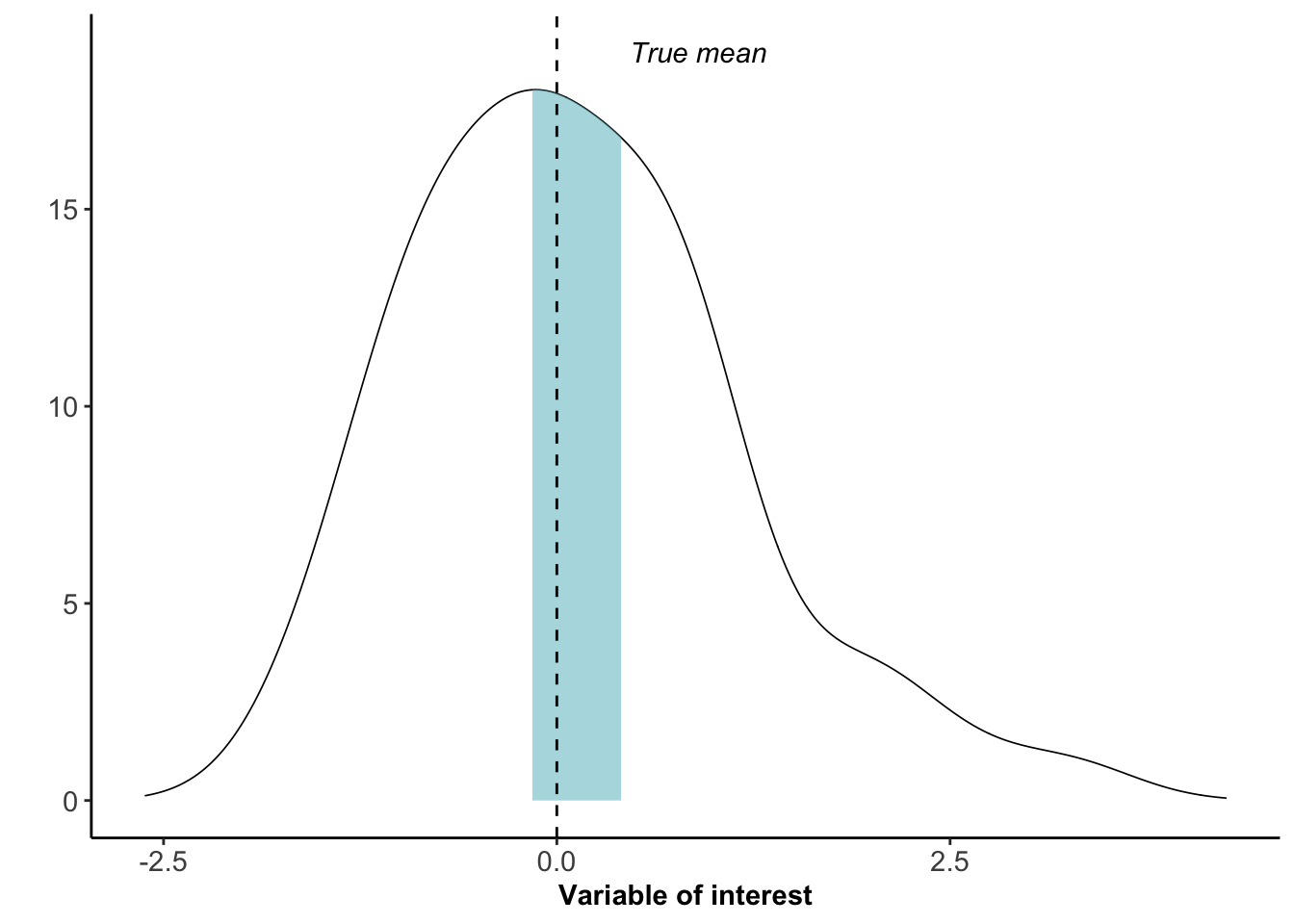
Data visualization: ambiguity as a fellow traveler
Research that is being done about how to visualize uncertainty in data visualizations. Marx, V. Nat Methods 10, 613–615 (2013). https://doi.org/10.1038/nmeth.2530
Data visualization standards
Collection of guidance and resources to help create better data visualizations with less effort.
Colour
What to consider when choosing colors for data visualization
A short, visual guide on things to keep in mind when using colour, such as when and how to use colour gradients, the colour grey, etc.
ColorBrewer: Color Advice for Maps
Tool to generate colour palettes for visualizations with colorblind-friendly options. You can also use these palettes in R using the RColorBrewer package, and the scale_*_brewer() (for discrete palettes) or scale_*_distiller() (for continuous palettes) functions in ggplot2.
Color.review
Tool to pick or verify colour palettes with high relative contrast between colours, to ensure your information is readable for everyone.
Coblis — Color Blindness Simulator
Tool to upload an image and view it as they would appear to a colorblind person, with the option to simulate several color-vision deficiencies.
500+ Named Colours with rgb and hex values
List of named colours along with their hex values.
CartoDB/CartoColor
CARTOColors are a set of custom color palettes built on top of well-known standards for color use on maps, with next generation enhancements for the web and CARTO basemaps. Choose from a selection of sequential, diverging, or qualitative schemes for your next CARTO powered visualization using their online module.